제2장 데이터 핸들링 1
DataFrame 선언하기
import numpy as np
import pandas as pd
dataset = np.array([['kor', 70], ['math', 80]])
df = pd.DataFrame(dataset, columns=['class', 'score'])
# list, dictionary, ndarray 등 다양한 데이터 타입 객체를 DataFrame으로 선언 가능
# pd.DataFrame([['kor', 70], ['math', 80]], columns=['class', 'score'])
# pd.DataFrame({'class':['kor, 'math'], 'score':[70,80]})
df
Series 선언하기
value = 10
ds = pd.Series({'idx 1':value, 'idx 2':value}, name='class') # Series 선언하기
ds
DataFrame 읽고 저장하기
file_path = NULL # 'dataset/data.csv'
data = pd.read_csv(file_path, na_values='NA', encoding='utf8') # 데이터에 한국어 포함이면 utf8data.to_csv('result.csv', header=True, index=True, encoding='utf8') # 데이터 저장DataFrame 요약(통계정보 확인하기) (info(), describe())
df.info()
df.describe()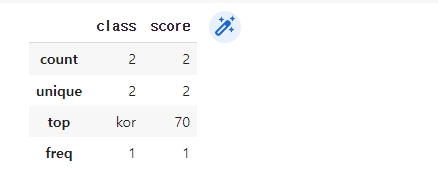
DataFrame 인덱스 추가, 리셋
df.index = ['A','B'] # index 변경
df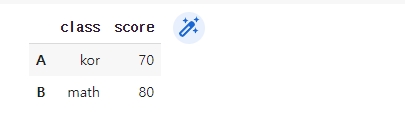
df.set_index('class', drop=True, append=False, inplace=True)
df
# 'A'칼럼을 인덱스로 사용하고자 할 때. drop=True는 기존 컬럼을 df에서 삭제함. append=True는 기존 인덱스 삭제함. inplace=True는 원본 객체를 변경함.
df.reset_index(drop=False, inplace=True) # 인덱스를 0부터 시작하는 정수로 재설정.
Dataframe 컬럼명 확인 및 변경 (columns())
df.columns #칼럼명 조회
new_df = df.columns.str.replace('class', 'new_class') # df 컬럼명에 있는 모든 'class'글자를 'new_class'로 바꾸기
new_df # 새롭게 객체를 지정해줘야한다!!! -> 왜 일까??
데이터 타입 확인 및 변경 (astype())
df.dtypes # 데이터 타입 확인
df['class'].astype('int') # 'class'칼럼의 데이터 타입 int로 변경
row/column 선택 추가 삭제 (loc(), iloc() 함수)
from sklearn.datasets import load_iris
iris = load_iris()
iris = pd.DataFrame(iris.data, columns=iris.feature_names)
iris[1:4] # row 선택하기
iris['sepal length (cm)'].head(4) # column 선택하기
iris.iloc[[1,3,5], 2:4] # DataFrame.iloc[row, columns], 2:4는 [2,3] list와 동일. iloc 안에는 칼럼을 무조건 int로 써야함
iris.loc[[1,3,5], ['sepal length (cm)', 'petal length (cm)']] # loc 안에는 칼럼은 무조건 칼럼명으로 써야함.
Dataframe 데이터 변경하기
iris.loc[[0],['sepal length (cm)']] = 100 # sepal length (cm) 칼럼의 첫번째(index 0) 데이터 값을 100으로 변경row/column 추가
# row 추가
new_students = pd.DataFrame({'국어':[70,80]}, index=['A', 'B'])
new_student2 = pd.Series({'국어':85}, name='C')
new_student3 = new_students.append(new_student2)
new_student3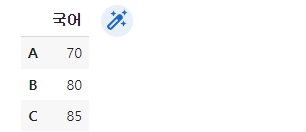
#dictionary 자료형으로 행을 추가할 경우, append에서 ignore_index=True를 꼭 해주어야 한다.
ns = {'국어':[75],'수학':[80],'영어':[80]} # dictionary를 dataframe으로 바꾸려면 value에 list[] 처리하기!!
ns = pd.DataFrame(ns)
ns2 = ns.append({'국어':70,'수학':85,'영어':60}, ignore_index=True)
ns2
# column추가
ns2['과학'] = [40,90]
ns2['총점'] = ns2['국어'] + ns2['수학'] + ns2['영어'] + ns2['과학']
ns2
row/column 삭제 (drop())
ns2.drop(index명, inplace =True)
#inplace=False면 작업 수행의 결과를 복사본으로 반환, True면 수행하나 None을 반환