제3장 EDA와 시각화 3
- 목 차
1. 막대그래프
2. 히스토그램
3. 상자그림
4. 산점도
5. 수평선 수직선 그래프
6. 함수식 그래프
7. 회귀선 그래프
8. 꺾은선 그래프
9. 산점도 행렬 + KDE그래프
10. 상관계수 행렬 그래프
9. 산점도 행렬 (+ KDE그래프)
# 산점도 행렬이란 두 개 이상의 변수가 있는 데이터에서 변수들 간의 산점도를 그린 그래프.
# 실제 데이터의 분포를 한눈에 파악할 수 있고, 2차원 이상의 관계가 존재하는 지의 여부도 파악할 수 있는 장점이 있다.
# 각 변수의 밀도그래프(KDE, Histogram)를 함께 그려 데이터의 분포와 변수들 간의 관계를 함께 볼 수도 있다.'''
1. 대각선의 히스토그램을 통해 이상치 확인
2. 종속변수와 설병변수들 간의 관계를 시각적으로 판단.
3. 종속변수가 수치형일 경우 : 각 설명변수와의 직선 상관관계 비교
4. 종속변수가 범주형일 경우 : 종속변수를 잘 구분하는 설명변수를 파악
5. 설명변수 간의 직선 함수관계를 파악하여 다중공선성 문제를 진단
'''# scatter_matrix(data, alpha = 0.5, figsize=(8,8), diagonal = 'hist')
# alpha는 투명도(0~1), figsize는 그래프 크기, diagonal는 대각선의 밀도 그래프 종류(hist, kde)
import pandas as pd
from sklearn.datasets import load_iris
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
iris = load_iris()
iris = pd.DataFrame(iris.data, columns = iris.feature_names)
iris['Class'] = load_iris().target
iris['Class'] = iris['Class'].map({0:'Setosa', 1: 'Versicolour', 2:'Virginica'})
# 산점도 행렬
scatter_matrix(iris, alpha = 0.5, figsize = (8,8), diagonal = 'hist')
plt.show()
# target 범주별 색깔을 다르게 지정하여 산점도 행렬을 그릴 수도 있다. 두 칼럼 간의 범주별 관계의 유형과 강도의 차이를 파악하고 비교할 수 있다.
# sns.pairplot(data, diag_kind = 'auto', hue = 'Class'), diag_kind = {auto, hist, kde}, hue는 색을 구분할 타깃 변수
import seaborn as sns
sns.pairplot(iris, diag_kind = 'auto', hue = 'Class')
plt.show()

10. 상관계수 행렬 그래프
# data = data.corr(method='pearson')
#method로는 'pearson', 'kendall', 'spearman'이 있다.
# sns.heatmap(data, xticklabels = data.columns, yticklabels = data.columns, cmap = 'RdBu_r', annot = True)
# xticklabels는 x축의 라벨명, yticklabels는 y축의 라벨명, cmap은 히트맵의 색깔 지정, annot=True일 경우 상관계수를 텍스트로 표시.
iris_corr = iris.drop(columns= 'Class').corr(method = 'pearson')
sns.heatmap(iris_corr, xticklabels = iris_corr.columns, yticklabels = iris_corr.columns, cmap = 'RdBu_r', annot = True)
plt.show()
# 상관계수 행렬표
iris_corr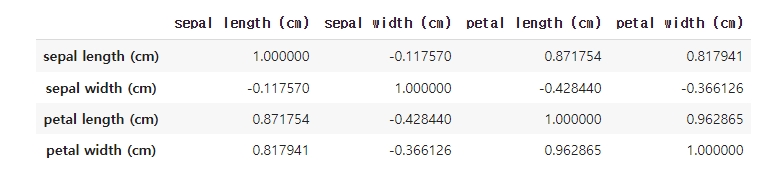
# 0.8 이상 : 강한 상관관계
# 0 ~ 0.4 : 거의 상관 없음- Pandas Profiling 소개
'''
데이터프레임에 대한 탐색적 분석을 한 줄의 코드로 수행할 수 있는 라이브러리. EDA에 소모되는 시간을 획기적으로 줄일 수 있지만, 시험장 버전 확인 후 준비할 것.
통계정보, 컬럼null, 히스토그램, 막대그래프, 칼럼별 산점도, 상관행렬 그래프, 값의 개수 및 Null값 존재 여부확인, 가장 처음와 마지막 10개 값, 중복 행 체크 등...
'''# COLAB 환경에서
!pip uninstall pandas_profiling
!pip install pandas-profiling[notebook]from pandas_profiling import ProfileReport
ProfileReport(iris)
# 왜인지 COLAB에서 오류가 뜬다.. TypeError: concat() got an unexpected keyword argument 'join_axes'